Summary
Node 的特性是单线程、非阻塞时I/O
collection
v8
阻塞、非阻塞和同步、异步
阻塞和非阻塞 I/O 其实是针对操作系统内核而言的,而不是 nodejs 本身。阻塞 I/O 的特点就是一定要等到操作系统完成所有操作后才表示调用结束,而非阻塞 I/O 是调用后立马返回,不用等操作系统内核完成操作。
阻塞I/O造成CPU等待I/O,CPU的处理能力不能充分利用,浪费等待时间。 非阻塞I/O不带数据直接返回,性能提高很大,但完整的I/O并没有完成,所有应用程序需要重复调用I/O操作来确认是否完成,这种叫轮询
nodejs中的异步 I/O 采用多线程的方式,由 EventLoop、I/O 观察者,请求对象、线程池四大要素相互配合,共同实现。
Js
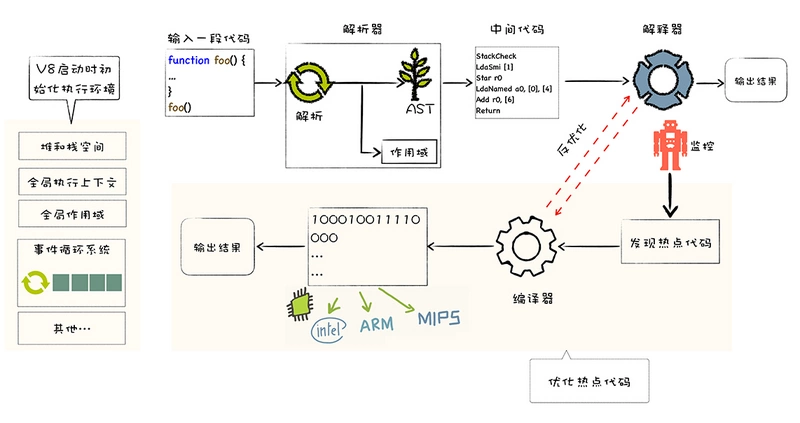
JS属于解释型语言,对于解释型的语言说,解释器会对源代码做如下分析:
- 通过词法分析和语法分析生成 AST(抽象语法树),接下来会生成执行上下文
- 将 AST 转换为字节码(字节码是介于
AST和机器码之间的一种代码,但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码然后执行。) - 由解释器逐行执行字节码,遇到热点代码启动编译器进行编译,生成对应的机器码, 以优化执行效率。
如果把AST直接转成机器码给V8执行,也可以,但转成的机器码的体积太大,引发了严重的内存占用问题。
所以解释器是将字节码转成机器码。
在执行字节码的过程中,如果发现某一部分代码重复出现,那么 V8 将它记做热点代码(HotSpot),然后将这段代码编译成机器码保存起来,这个用来编译的工具就是V8的编译器(也叫做TurboFan) , 因此在这样的机制下,代码执行的时间越久,那么执行效率会越来越高,因为有越来越多的字节码被标记为热点代码,遇到它们时直接执行相应的机器码,不用再次将转换为机器码。
编译器和解释器的 根本区别在于前者会编译生成二进制文件但后者不会。
并且,这种字节码跟编译器和解释器结合的技术,称之为即时编译(JIT)。
asynclocalstorage
const http = require('http');
function handler1(req, res) {
console.log(req.url);
}
function handler2(req, res) {
console.log(req.url);
}
http.createServer((req, res) => {
handler1(req, res);
handler2(req, res);
res.end();
}).listen();上面的代码中,每次收到一个请求时都会执行 handler1 和 handler2,为了在不同的地方里都能拿到对应的请求上下文,只能逐级进行传递,如果业务逻辑很复杂,这个维护性是非常差的
AsyncLocalStorage 是基于 Async Hooks 实现的,它通过上下文传递实现了异步代码的上下文共享和隔离。
const { AsyncLocalStorage } = require('async_hooks');
const asyncLocalStorage = new AsyncLocalStorage();
function logWithId(msg) {
const id = asyncLocalStorage.getStore();
console.log(`${id !== undefined ? id : '-'}:`, msg);
}
asyncLocalStorage.run(1, () => {
logWithId('start');
setImmediate(() => {
logWithId('finish');
});
});输出:
1: start
1: finish两个 logWithId 共享了同一个上下文,这个上下文是由 run 函数设置的 1
const http = require('http');
const { AsyncLocalStorage } = require('async_hooks');
const asyncLocalStorage = new AsyncLocalStorage();
function handler1() {
const { req } = asyncLocalStorage.getStore();
console.log(req.url);
}
function handler2() {
setImmediate(() => {
const { req } = asyncLocalStorage.getStore();
console.log(req.url);
});
}
http.createServer((req, res) => {
asyncLocalStorage.run({ req, res }, () => {
handler1();
handler2();
});
res.end();
}).listen(9999, () => {
http.get({ port: 9999, path: '/test' })
});不需要逐级地传递请求上下文并且可以在任意异步代码中获取请求上下文
Cookie、Session、Token、JWT
简单 token 的组成: uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串)
JWT 的三个部分依次如下:
- Header(头部)
- Payload(负载)
- Signature(签名)
header 部分指定了该 JWT 使用的签名算法:
header = '{"alg":"HS256","typ":"JWT"}' // `HS256` 表示使用了 HMAC-SHA256 来生成签名。payload 部分表明了 JWT 的意图:
payload = '{"loggedInAs":"admin","iat":1422779638}' //iat 表示令牌生成的时间signature 部分为 JWT 的签名,主要为了让 JWT 不能被随意篡改,签名的方法分为两个步骤:
- 输入
base64url编码的 header 部分、.、base64url编码的 payload 部分,输出unsignedToken。 - 输入服务器端私钥、unsignedToken,输出 signature 签名。
const base64Header = encodeBase64(header)
const base64Payload = encodeBase64(payload)
const unsignedToken = `${base64Header}.${base64Payload}`
const key = '服务器私钥'
signature = HMAC(key, unsignedToken)最后的 Token 计算如下:
const base64Header = encodeBase64(header)
const base64Payload = encodeBase64(payload)
const base64Signature = encodeBase64(signature)
token = `${base64Header}.${base64Payload}.${base64Signature}`服务器在判断 Token 时:
const [base64Header, base64Payload, base64Signature] = token.split('.')
const signature1 = decodeBase64(base64Signature)
const unsignedToken = `${base64Header}.${base64Payload}`
const signature2 = HMAC('服务器私钥', unsignedToken)
if (signature1 === signature2) {
return '签名验证成功,token 没有被篡改'
}
const payload = decodeBase64(base64Payload)
if (new Date() - payload.iat < 'token 有效期') {
return 'token 有效'
}Token 和 JWT 的区别
相同:
- 都是访问资源的令牌
- 都可以记录用户的信息
- 都是使服务端无状态化
- 都是只有验证成功后,客户端才能访问服务端上受保护的资源
区别:
- Token:服务端验证客户端发送过来的 Token 时,还需要查询数据库获取用户信息,然后验证 Token 是否有效。
- JWT: 将 Token 和 Payload 加密后存储于客户端,服务端只需要使用密钥解密进行校验(校验也是 JWT 自己实现的)即可,不需要查询或者减少查询数据库,因为 JWT 自包含了用户信息和加密的数据。
两种 Token:
1. 去中心化的 JWT token
- 优点:
- 去中心化,便于分布式系统使用
- 基本信息可以直接放在 token 中。 username,nickname,role
- 功能权限信息可以直接放在 token 中。用 bit 位表示用户所具有的功能权限。
- 缺点:服务端无法主动让 token 失效
2. 中心化的 redis token / memory session 等
- 优点:服务端可以主动让 token 失效
- 缺点:每次都要进行 redis 查询。占用 redis 存储空间。
优化方案:
3.1 Jwt Token 中,增加 TokenId 字段。 3.2 将 TokenId 字段存储在 redis 中,用来让服务端可以主动控制 token 失效 3.3 牺牲了 JWT 去中心化的特点。 3.4 使用非对称加密。颁发 token 的认证服务器存储私钥:私钥生成签名。其他业务系统存储公钥:公钥验证签名。
方案 2 和 3.2 的区别:
方案 2:redis 存储的是 token 的白名单。用户的其他信息也要放在 redis 中存储。需要占用较大的 redis 空间和查询次数。
方案 3.2 :这里的 redis 只存储 tokenId 的黑名单,同时 redis 也可以分布式部署,读写分离。token 认证服务器操作 redis 的 master,其他 redis 同步 master 的数据
基本知识点
__dirname: 总是返回被执行的 js 所在文件夹的绝对路径;__filename: 总是返回被执行的 js 的绝对路径;process.cwd(): 总是返回运行 node 命令时所在的文件夹的绝对路径;path.dirname(): 返回 path 的目录名path.join():所有给定的 path 片段连接到一起,然后规范化生成的路径path.resolve():方法会将路径或路径片段的序列解析为绝对路径,解析为相对于当前目录的绝对路径,相当于 cd 命令
Nest.js
控制反转
控制反转(Inversion of Control,缩写为 IoC)是一种设计原则,通过反转程序逻辑来降低代码之间的耦合性。
控制反转容器(IoC 容器)是某一种具体的工具或者框架,用来执行从内部程序反转出来的代码逻辑,从而提高代码的复用性和可读性。我们常常用到的 DI 工具,就扮演了 IoC 容器的角色,连接着所有的对象和其依赖。
依赖注入
依赖注入是控制反转的一种具体地实现,通过放弃程序内部对象生命创建的控制,由外部去创建并注入依赖的对象。
依赖注入的方法主要是以下四种:
- 基于接口。实现特定接口以供外部容器注入所依赖类型的对象。
- 基于 set 方法。实现特定属性的 public set 方法,来让外部容器调用传入所依赖类型的对象。
- 基于构造函数。实现特定参数的构造函数,在新建对象时传入所依赖类型的对象。
- 基于注解,在私有变量前加类似
@Inject的注解,让工具或者框架能够分析依赖,自动注入依赖。