框架面试题
1、React Vue 使用感受
相同点:
- 虚拟 DOM
- 组件化
- 保持对视图的关注
- 数据驱动视图
- 都有支持 native 的方案
不同点:
- state 状态管理 vs 对象属性 get,set。
- vue 实现了数据的双向绑定 v-model,而组件之间的 props 传递是单向的,react 数据流动是单向的。
组件更新粒度
Vue 对于响应式属性的更新,只会精确更新依赖收集的当前组件,而不会递归的去更新子组件,这也是它性能强大的原因之一。
<template>
<div>
{{ msg }}
<ChildComponent />
</div>
</template>在触发 this.msg = 'Hello, Changed~'的时候,会触发组件的更新,视图的重新渲染。
但是 <ChildComponent /> 这个组件其实是不会重新渲染的。其实每个组件都有自己的渲染 watcher,它掌管了当前组件的视图更新,但是并不会掌管ChildComponent的更新。
而 React 在类似的场景下是自顶向下的进行递归更新的,也就是说,React 中假如 ChildComponent 里还有十层嵌套子元素,那么所有层次都会递归的重新render(在不进行手动优化的情况下),这是性能上的灾难。(因此,React 创造了Fiber,创造了异步渲染,其实本质上是弥补被自己搞砸了的性能)。 他们能用收集依赖的这套体系吗?不能,因为他们遵从Immutable的设计思想,永远不在原对象上修改属性,那么基于 Object.defineProperty 或 Proxy 的响应式依赖收集机制就无从下手了(你永远返回一个新的对象,我哪知道你修改了旧对象的哪部分?) 同时,由于没有响应式的收集依赖,React 只能递归的把所有子组件都重新 render一遍(除了memo和shouldComponentUpdate这些优化手段),然后再通过 diff算法 决定要更新哪部分的视图,这个递归的过程叫做 reconciler,听起来很酷,但是性能很灾难。
运行时优化
在 React 应用中,当某个组件的状态发生变化时,它会以该组件为根,重新渲染整个组件子树,开发者不得不手动使用 shouldComponentUpdate 去优化性能。
在 Vue 组件的依赖是在渲染过程中自动追踪的,开发者不再需要考虑此类优化。另外 Vue 还做了很多其他方面的优化,例如:标记静态节点,优化静态循环等。
总结:Vue 在运行时帮我们做了很多优化了处理,开发者可以直接上手,React 则是由开发者自己去处理优化,让程序有更多的定制化。
JSX vs Templates
JSX 中你可以使用完整的编程语言 JavaScript 功能来构建你的视图页面。比如你可以使用临时变量、JS 自带的流程控制、以及直接引用当前 JS 作用域中的值等等。
Templates 对于很多习惯了 HTML 的开发者来说,模板比起 JSX 读写起来更自然。基于 HTML 的模板使得将已有的应用逐步迁移到 Vue 更为容易。你甚至可以使用其他模板预处理器,比如 Pug 来书写 Vue 的模板。
总结:Vue 在模板上实现定制化,可以使用类 HTML 模板,以及可以使用 JSX,React 则是推荐 JSX。
生态圈
Vue 的路由库和状态管理库都是由官方维护支持且与核心库同步更新的。
React 的路由库和状态管理库是由社区维护,因此创建了一个更分散的生态系统。React 的生态系统相比 Vue 更加繁荣。
2、单向数据流和双向数据流有什么区别
单向数据流
优点:
- 所有状态的改变可记录、可跟踪,源头易追溯。
- 所有数据只有一份,组件数据只有唯一的入口和出口,使得程序更直观更容易理解,有利于应用的可维护性。
- 一旦数据变化,就去更新页面(data -> 页面),没有(页面 -> data)。
- 如果用户在页面上做了变动,需要手动更新数据。
缺点:
- HTML 代码渲染完成,无法改变,新数据到来时,就会整合新数据和模板重新渲染。
- 代码量上升,数据流转换过程变长,需要进行统一的数据流管理,例如:redux。
双向数据流
双向绑定 = 单向绑定 + UI 事件监听。
优点:
- 用户在视图上的修改会自动同步到数据模型中去,数据模型中值的变化也会立刻同步到视图中去。
- 在表单交互较多的场景下,会简化大量业务无关的代码。
缺点:
- 无法追踪局部状态的变化。
- 可能存在暗箱操作,增加了出错时 debug 的难度。
- 由于组件数据变化来源入口不止一个,数据流转方向易混乱,如果不加以控制,容易出错。
3、React 优点
- 函数式编程思想,无状态组件,同样的 prop 对应同样地输出。
- 虚拟 dom,fiber,底层优化,提高渲染效率。
- 模块化思想,复用性更强。
- 单向数据流,让事情一目了然。
- 以 js 为中心,使用 jsx 开发页面,css in js 书写样式。
- 支持服务器端渲染。
- 一套代码多端运行。
缺点:
- 只是视图层,构建大型项目的话,需要引入 redux 和 react-router 等相关的东西。
4、Vue 优点
- 类 HTML 模板语法,更容易上手。
- 模块化思想,复用性强。
- 虚拟 dom,运行时优化,提高渲染效率。
- 支持双向数据绑定,易用性强。
- 支持服务器端渲染。
缺点:
- 社区不如 react,大多是中国开发者。
- 生态圈不够,vue 全家桶都是 vue 官方自己出的东西。
5、webpack 插件怎么编写
webpack 就像是一条生产线,要经过一系列流程处理之后才能将源文件转换成输出结果。
webpack plugin 实质就是一个类,在被创建的时候,会监听 webpack 生产线上的事件,然后加入生产线中,改变生产线输出。
webpack 启动后,会读取配置中的 plugins,并创建对应实例,在 webpack 初始化 compiler 对象之后,再调用 plugin 中的 apply 方法,把 compiler 注入到插件中。
class HelloAsyncPlugin {
apply(compiler) {
// tapAsync() 基于回调(callback-based)
compiler.hooks.emit.tapAsync('HelloAsyncPlugin', function(
compilation,
callback
) {
setTimeout(function() {
console.log('Done with async work...');
callback();
}, 1000);
});
// tapPromise() 基于 promise(promise-based)
compiler.hooks.emit.tapPromise('HelloAsyncPlugin', compilation => {
return doSomethingAsync().then(() => {
console.log('Done with async work...');
});
});
// 原先基本的 tap() 也在这里列出:
compiler.hooks.emit.tap('HelloAsyncPlugin', () => {
// 这里没有异步任务
console.log('Done with sync work...');
});
}
}
module.exports = HelloAsyncPlugin;6、webpack loader 编写
webpack loader 实质就是一个function,function 中会被注入需要被处理的资源,然后加以处理。
loader 的执行时会先执行最后的 loader,然后再执行前一个 loader,如果想按顺序执行,可以定义 pitch 方法。
loader 一般会使用 acorn 将代码转换过成 ast 语法树,然后再进行对应的操作,最后再转换会字符串。
import { getOptions } from 'loader-utils';
import validateOptions from 'schema-utils';
const schema = {
type: 'object',
properties: {
test: {
type: 'string'
}
}
};
module.exports = function(source) {
const options = getOptions(this);
validateOptions(schema, options, 'Example Loader');
// 对资源应用一些转换……
return `export default ${JSON.stringify(source)}`;
};
// pitch方法,在捕获阶段执行的函数
module.exports.pitch = function(remainingRequest, precedingRequest, data) {
data.value = 42;
};7、webpack 插件之间怎么互相通信
在 webpack 中,通过 tapable 管理运行时的各种事件流,不同的 webpack plugins 可以通过自定义事件相互通信。
例如:在 Bplugin 中监听 Aplugin 中的事件
// A 插件
const SyncHook = require('tapable').SyncHook;
class APlugin {
apply(compiler) {
if (compiler.hooks.myCustomHook) throw new Error('Already in use');
// 声明一个自定义事件,并初始化需要传递的参数。
compiler.hooks.myCustomHook = new SyncHook(['参数1', '参数2']);
// 在当前插件中监听自定义事件
compiler.hooks.myCustomHook.tap('APlugin', (a, b) =>
console.log('获取到参数:', a, b)
);
// 可以在任意的钩子函数中去触发自定义事件
compiler.hooks.compilation.tap('APlugin', compilation => {
compilation.hooks.afterOptimizeChunkAssets.tap('APlugin', chunks => {
compiler.hooks.myCustomHook.call('a', 'b');
});
});
}
}
// B 插件
class BPlugin {
apply(compiler) {
// 监听A组件定义的事件
compiler.hooks.myCustomHook.tap('BPlugin', (a, b) =>
console.log('获取到参数:', a, b)
);
}
}8、React 中是否必须将所有状态都放入 Redux
我们都知道,如果把状态都存在 redux 中,就可以编写出更多无状态的组件。
无状态组件优点:
- 代码整洁、可读性高
- 无状态组件的性能好
个人理解,并不是所有的 state 都存放在 redux 里比较好,应该考虑一下几点:
- 该应用程序的其他部分是否关心此数据?
- 您是否需要能够根据此原始数据创建更多派生数据?
- 是否使用相同的数据来驱动多个组件?
- 能够将此状态恢复到给定时间点?
- 你想缓存数据?
如果你没有以上的需要,就不要把 state 放入 redux 中。
9. 请描述一下 Vuex 中的几大模块之间的作用
vuex 的原理很简单,简单来说:
- view dispatch 一个 action。
- action commit 一个 mutation。
- mutation 修改 store 后,重新更新视图。
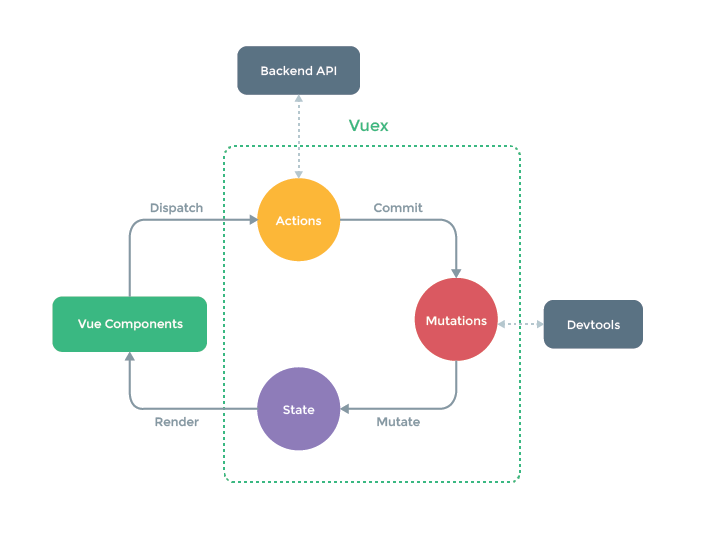
// 创建一个store,如果需要拆分,可以将不同的模块挂载到 modules 上。
const store = new Vuex.Store({
// store 中的对象
state: {
count: 0
},
// 唯一改变 store 的方法,只能是同步更新
mutations: {
increment(state) {
state.count++;
}
},
// action 派发一个 mutation,可以使用异步方法
actions: {
increment(context) {
setTimeout(() => {
context.commit('increment');
}, 1500);
}
},
// 派生 store 中的状态
getters: {
showCount: state => {
return '当前的count是:' + state.count;
}
}
});获取声明的 store,为了方便调用 store 上的 state,getter,action,vuex 提供了 mapState,mapGetters,mapActions 方法。
import { mapState, mapGetters, mapActions } from 'vuex';
export default {
computed: {
otherCount(){
return 123;
},
...mapState({
count: state => state.count// 把 `this.count` 映射为 `this.$store.state.count`
}),
...mapGetters([
'showCount'// 把 `this.showCount` 映射为 `this.$store.getters.showCount`
])
},
methods:{
...mapActions([
'increment'// 将 `this.increment()` 映射为 `this.$store.dispatch('increment')`
]),
}
}10、说说你理解的 Flutter
在 Flutter 诞生之前,已经有许多跨平台 UI 框架的方案,比如基于 WebView 的 Cordova、AppCan 等,还有使用 HTML + JS 渲染成原生控件的 React Native、Weex 等。
基于 WebView 的框架优点很明显,它们几乎可以完全继承现代 Web 开发的所有成果(丰富地控件库、满足各种需求的页面框架、完全的动态化、自动化测试工具等),当然也包括 Web 开发人员,不需要太多的学习和迁移成本就可以开发一个 App。同时 WebView 框架也有一个致命的缺点,那就是 WebView 的渲染效率和 JS 执行性能太差。再加上 Android 各个系统版本和设备厂商的定制,很难保证所在所有设备上都能提供一致的体验。
为了解决 WebView 性能差的问题,以 React Native 为代表的一类框架将最终渲染工作交还给了系统,虽然同样使用类 HTML + JS 的 UI 构建逻辑,但是最终会生成对应的自定义原生控件,以充分利用原生控件相对于 WebView 的较高地绘制效率。与此同时这种策略也将框架本身和 App 开发者绑在了系统的控件系统上,不仅框架本身需要处理大量平台相关的逻辑,随着系统版本变化和 API 的变化,开发者可能也需要处理不同平台的差异,甚至有些特性只能在部分平台上实现,这样框架的跨平台特性就会大打折扣。
Flutter 则开辟了一种全新的思路,从头到尾重写一套跨平台的 UI 框架,包括 UI 控件、渲染逻辑甚至开发语言。渲染引擎依靠跨平台的 Skia 图形库来实现,依赖系统的只有图形绘制相关的接口,可以在最大程度上保证不同平台、不同设备的体验一致性,逻辑处理使用支持 AOT 的 Dart 语言,执行效率也比 JS 高得多。
11、在 React 中,为什么最好在 ComponentDidMount 中发起请求
1、react fiber 中可能多次调用 render 之前的生命周期函数,可能会请求多次。
2、componentWillMount 在服务器端渲染时,服务器端会执行一次,客户端也会执行一次。
3、如果请求在 componentWillMount,react 并没有挂载到 dom 上,这时候 setState 可能会有问题。
12、简述一下 React 中的事件机制
React 其实自己实现了一套事件机制,首先我们考虑一下以下代码:
const Test = ({ list, handleClick }) => (
list.map((item, index) => (
<span onClick={handleClick} key={index}>{index}</span>
))
)以上类似代码想必大家经常会写到,但是你是否考虑过点击事件是否绑定在了每一个标签上?实际上并不是,JSX 上写的事件并没有绑定在对应的真实 DOM 上,而是通过事件代理的方式,将所有的事件都统一绑定在了 document 上。这样的方式不仅减少了内存消耗,还能在组件挂载销毁时统一订阅和移除事件。
另外冒泡到 document 上的事件也不是原生浏览器事件,而是 React 自己实现的合成事件。因此不能使用 event.stopPropagation 阻止事件冒泡,而应该使用 event.preventDefault。
TIP
- 合成事件首先抹平了浏览器之间的兼容问题,另外这是一个跨浏览器原生事件包装器,赋予了跨浏览器开发的能力。
- 合成事件在运行时,有一个事件池专门来管理它们的创建和销毁,当事件需要被使用时,就会从池子中复用对象,事件回调结束后,就会销毁事件对象上的属性,从而便于下次复用事件对象。
13、什么是可控组件和不可控组件
在 html 中,像<input>,<textarea>, 和 <select>这类表单元素会维持自身的值 value,并根据用户输入进行更新。但在 react 中,可变的状态是保存在组件的 state 中的,并且只能用 setState 方法进行更新。
import React, {useState, useEffect} from 'react'
interface Props {
value?: string,
maxLength?: number
}
export default function InputItem({value, maxLength}: Props) {
const [state, setState] = useState('')
useEffect(() => {
value && setState(value) // 这里能通过props控制state
}, [value])
function updateValue(inputValue: string) {
if (maxLength !== undefined && inputValue.length > maxLength) return
else setState(inputValue)
}
return (
<div className='input-item'>
<input value={state} onInput={(e => updateValue(e.currentTarget.value))} style={{ paddingRight: maxLength !== undefined ? '36px' : '10px'}}/>
{ maxLength !== undefined &&
<span>{ state.length + '/' + maxLength}</span>
}
</div>
)
}通过 react 统一管理状态后的组件,又叫做可控组件。
14、React 异步渲染原理
React 不会保证在 setState 之后,能够立刻拿到改变的结果。
setState 渲染流程如下:
- 在 setState 中调用了 enqueueSetState 方法将传入的 state 放到一个队列中。
- enqueueSetState 中先是找到需渲染组件并将新的 state 并入该组件的需更新的 state 队列中,接下来调用了 enqueueUpdate 方法。
- isBatchingUpdates 表示是否在一个更新组件的事务流中。
- 已在事务流中,将需更新的组件放入 dirtyComponents 中,在下一次渲染时才会更新 state。
- 未在事务流中,调用 batchedUpdates 方法进入更新流程,进入流程后,会将 isBatchingUpdates 设置为 true。
这里衍生出了一个问题,什么时候会标识 isBatchingUpdates 为 true?
- 当处于生命周期 render 之后的生命周期中。
- 合成事件中(jsx 中的事件都是合成事件)。
案例:在 setTimeout 中执行 setstate 时,没有在 react 事务流中,所以会直接进入更新路程,同步渲染。
15、React Dom Diff 原理
React dom diff 操作流程如下:
- 深度优先遍历
- 同层节点依次比较(跨层次比较时间复杂度高,性能低下)
- 只有一个子节点 (1)
- 比较节点类型,类型不一致,直接删除,替换。
- 比较节点属性,不一致,就修改属性值。
- 比较节点的 children。
- 子节点是一个数组。
- 无 key。
- newChild 和 oldChild 一对一比较和 (1) 比较方式一致。
- 有 key
- 通过 key 找到可以复用的 oldChild,然后进行移动操作,具体操作见下文。
- 无 key。
- 只有一个子节点 (1)
对于有 key 时的具体移动操作,React 使用了顺序优化手段,我们仔细看一下。
- 遍历新子节点 newChildren。
- lastIndex 用来存储寻找过程中遇到的最大老节点 oldChildren 的索引值。
- 找到第一个 newChild 对应的 oldChildren 中的索引 _mountIndex,并赋值给 lastIndex。
- 找到第二个 newChild,比较 lastIndex 和当前
newChild._mountIndex。- lastIndex <
child._mountIndex,证明在老节点中 child2 在 child1 之后,而新节点中 child2 在 child1 之后,顺序一致,不需要进行交换。- lastIndex =
child._mountIndex将 lastIndex 始终指向当前遍历中最大的 oldChildren 索引。
- lastIndex =
- lastIndex >
child._mountIndex,证明在老节点中 child2 在 child1 之前,而新节点中 child2 在 child1 之后,顺序不一致,则需要进行交换。- 按照 newChildren 的顺序进行排列。
- 由于 newChild2 在 newChild1 之后,则需要将 oldChild2 移动到 oldChild1 后面。
- lastIndex <
- 找到第三个 newChild,如果是一个新节点。
- 直接将该 newChild 插入到之前的节点后面。
- 找到第四个 newChild...
- 直到 newChildren 遍历完成。
- 遍历老子节点 oldChildren。
- 比较 oldChild 是否在 newChildren 中。
- 如果 oldChild 不在 newChildren 中,直接删除。
React Dom Diff 算法其实还是有一些问题,例如:将 [1,2,3,4,5],变成 [5,1,2,3,4],则会进行 4 次移动操作,所以,尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,在一定程度上会影响 React 的渲染性能。
其实,为了解决这个问题,Vue 使用了双端比较的方法。
16、Vue Dom Diff 算法原理
这里是指 Vue2.x 中的 Diff 算法,底层使用snabbdom库。
Vue 中的 Diff 算法,使用双端比较的原理进行 Dom 比较操作,避免这种多余的 DOM 移动。
例如:比较两个 children 数组,需要四个指针,分别指向 oldStartIdx、oldEndIdx、newStartIdx,newEndIdx。
- newChildren[newStartIdx] 和 oldChildren[oldStartIdx] 比较。
- 如果一致,直接复用节点,并将指针往后移
newStartIdx++;oldStartIdx++。 - 不一致,不可复用,则什么都不做。
- 如果一致,直接复用节点,并将指针往后移
- newChildren[newEndIdx] 和 oldChildren[oldEndIdx] 比较。
- 如果一致,直接复用节点,并将指针往后移
newEndIdx--;oldEndIdx--。 - 不一致,不可复用,则什么都不做。
- 如果一致,直接复用节点,并将指针往后移
- newChildren[newStartIdx] 和 oldChildren[oldEndIdx] 比较。
- 如果一致,直接将节点进行移动,并将指针往后移
newStartIdx++;oldEndIdx--。 - 不一致,不可复用,则什么都不做。
- 如果一致,直接将节点进行移动,并将指针往后移
- newChildren[newEndIdx] 和 oldChildren[oldStartIdx] 比较。
- 如果一致,直接将节点进行移动,并将指针往后移
newEndIdx--;oldStartIdx++。 - 不一致,不可复用,则什么都不做。
- 如果一致,直接将节点进行移动,并将指针往后移
- 如果上述条件都不满足,并且是一个新节点。
- 直接插入节点(这个时候可能导致页面重排)。
- 同时双指针往后移。
- 如果上述条件都不满足,但能找到 oldChildren 其他位置的 key 可以复用。
- 先将 oldChild 位置移动到新的位置上。
- 然后设置
oldChild.nodeValue = undefined。 - 同时双指针往后移。
- 当出现
newStartIdx>=newEndIdx表示 newChildren 越界。- 直接删除剩下的 oldChildren。
- 当出现
oldStartIdx>=oldEndIdx表示 oldChildren 越界。- 直接插入剩下的 newChildren。
具体的部分源码如下:
function updateChildren() {
var oldStartIdx = 0;
var newStartIdx = 0;
var oldEndIdx = oldCh.length - 1;
var newEndIdx = newCh.length - 1;
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// patchVnode();
// 节点相同,不做任何处理
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// patchVnode();
// 节点相同,不做任何处理
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// patchVnode();
// 首或尾一致,进行移动
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// patchVnode();
// 首或尾一致,进行移动
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
}
// 首尾都不一致,寻找是否能复用之前的其他节点,通过 key 进行判断
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx);
if (isUndef(idxInOld)) {
// 没有 key 标识,当成新节点,进行创建
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
} else {
// 通过 key 找到可以复用的节点
vnodeToMove = oldCh[idxInOld];
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
);
// 将老节点的值设置为 undefined
oldCh[idxInOld] = undefined;
canMove &&
nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm);
} else {
// 没有找到可以复用的节点,当成新节点,进行创建
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
}
}
newStartVnode = newCh[++newStartIdx];
}
}
// 如果老节点首尾指针交叉了,代表老节点都遍历完成了。
// 新节点length > 老节点 length
// 如果新节点没有遍历完,则直接将剩余节点插入进来。
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
refElm,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
} else if (newStartIdx > newEndIdx) {
// 如果新节点首尾指针交叉了,代表新节点都遍历完成了。
// 新节点length < 老节点 length
// 直接删除剩下的老节点。
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}在 Vue3 中将采用另外一种核心 Diff 算法,它借鉴于 ivi 和 inferno。
在进行 Dom Diff 算法之前,先进行预处理过程,将公共的首尾提取出来。
- 队首比较
oldChild[first] = newChild[first]。- 如果一致则,指针指向下一个节点。
- 如果不一致,则执行 vue2 的双端比较。
- 队尾比较
oldChild[last] = newChild[last]。- 如果一致则,指针指向下一个节点。
- 如果不一致,则执行 vue2 的双端比较。
双端比较时的优化:
- 判断是否有节点需要移动,将需要移动的节点加入 source 数组中。
- 根据 source 数组计算出一个最长递增子序列(计算出最小的移动)。
- 移动 Dom 操作。
17、React 16 Dom Diff 原理
React 16 之后,将所有的 Virtual Dom 都修改成了 Fiber Dom。
fiberNode 有几个比较重要的属性:
- child,指向该节点的第一个子节点。
- return,指向当前节点的父节点。
- sibling,指向当前节点的兄弟节点。
- alternate,指向 workInprocess Tree 中相同位置的节点。
- effectTag,副作用标识,标识该节点是否存在变化。
- updateQueue,当前节点中的更新队列(例:setState 多次产生的更新)。
更新方式如下:
- 克隆 CurrentFiber Tree,生成 WorkInprocess Tree。
- WorkInprocess Tree 表示即将渲染到页面上的新的状态,会在下文进行更新。
- 每一个 WorkInprocess Tree 上的节点的 alternate 指向 CurrentFiber Tree 上对应的节点。
- 循环 WorkInprocess Tree。
- 根据根节点的 child 深度优先向下遍历。
- 每找到一个节点,创建 update 对象,并 push 到 fiberNode 节点 updateQueue 属性上。
- 执行 processUpdateQueue 方法,生成新 state。
- 比较 newState 和 oldState。
- 一致,则跳过。
- 不一致,则打上 effectTag = Update 的标识。
- 每一个 effectTag 都代表一次 dom 操作,常见的有,Update,Delete 等
- 遍历完毕。
- 将所有打上 effectTag 标识的节点组成一个 effect list 链表。
- 循环该链表,执行对应的 Dom 操作。
- 将 WorkInprocess Tree 和 CurrentFiber Tree 进行交换。
- 即当前的 CurrentFiber Tree 变为更新后的状态树。
18、Redux 中间件处理原理
Redux 中的中间件其实是用柯里化函数编写而成的,例如 logger 中间件:
// logger 中间件
const loggerMiddle = store => next => action => {
console.log('old state', store.getState());
let result = next(action);
console.log('next state', store.getState());
return result;
};接下来我们分析一下中间件的处理过程:
- 执行 applyMiddleware([loggerMiddle]) 方法生成一个中间件执行函数 fn。
- 将 fn 作为 creteStore 中的第三个参数进行传入。
- creteStore 中的第三个参数如果存在,会进行 creteStore 覆盖的操作。
- 将 oldCreateStore 方法传入 fn 中,进行缓存,生成执行函数 fn1。
- 在 fn1 中执行接收 oldCreateStore 的参数,创建 oldStore。
- 将中间件集合通过 compose 函数,组合成一个新函数 fn3。
- 将老的 dispatch 传入 fn3,生成一个新的 dispatch。
- 用新的 dispatch 代替旧的 dispatch,实际上中间件就是对 dispatch 的增强。
- 这样在执行新 dispatch 时,就会一次触发执行中间件的操作。
Redux 中间件的执行顺序和 koa 很像,都是洋葱式执行顺序。
applyMiddleware([a, b, c]);
// aStart -- bStart -- cStart -- cEnd -- bEnd -- aEnd。19、Nodejs 中 setImmediate 和 setTimeout 的执行顺序
首先我们得知道 nodejs 的异步调度机制
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
});这道题没有正确答案,顺序有时候一致,有时候不一致。
1、首先要明白一点,在 nodejs 中 setTimeout(fn,0) 相当于 setTimeout(fn,1)。
2、在 nodejs 异步回调中,首先进入 timers 阶段,如果机器性能不好,进入该阶段时 1ms 已经过去了,那么 setTimeout 会首先执行。
3、如果机器性能好,进入 timers 阶段时,setTimeOut 还在等待 1ms ,这时会执行后面的阶段,当执行到 check 阶段时,会执行 setImmediate。
4、在下一个事件循环周期中,执行 setTimeout。
var fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});这个题的答案就明确了。
1、首先,在 poll 阶段执行 raedFile 函数,执行完成之后 setTimeout 和,setImmediate 都被加入到了对应的阶段。
2、poll 阶段执行完毕,由于没有其他的 io 操作,并且有设置 setImmediate,所以首先执行 setImmediate 方法。
4、在下一个事件循环周期中,执行 setTimeout。
综上所述:
- 如果两者都在主模块中调用,那么执行先后取决于进程性能,也就是随机。
- 如果两者都不在主模块调用(被一个异步操作包裹),那么 setImmediate 的回调永远先执行。